 容灾产品
容灾产品 备份产品
备份产品 大数据产品
大数据产品 云数据管理
云数据管理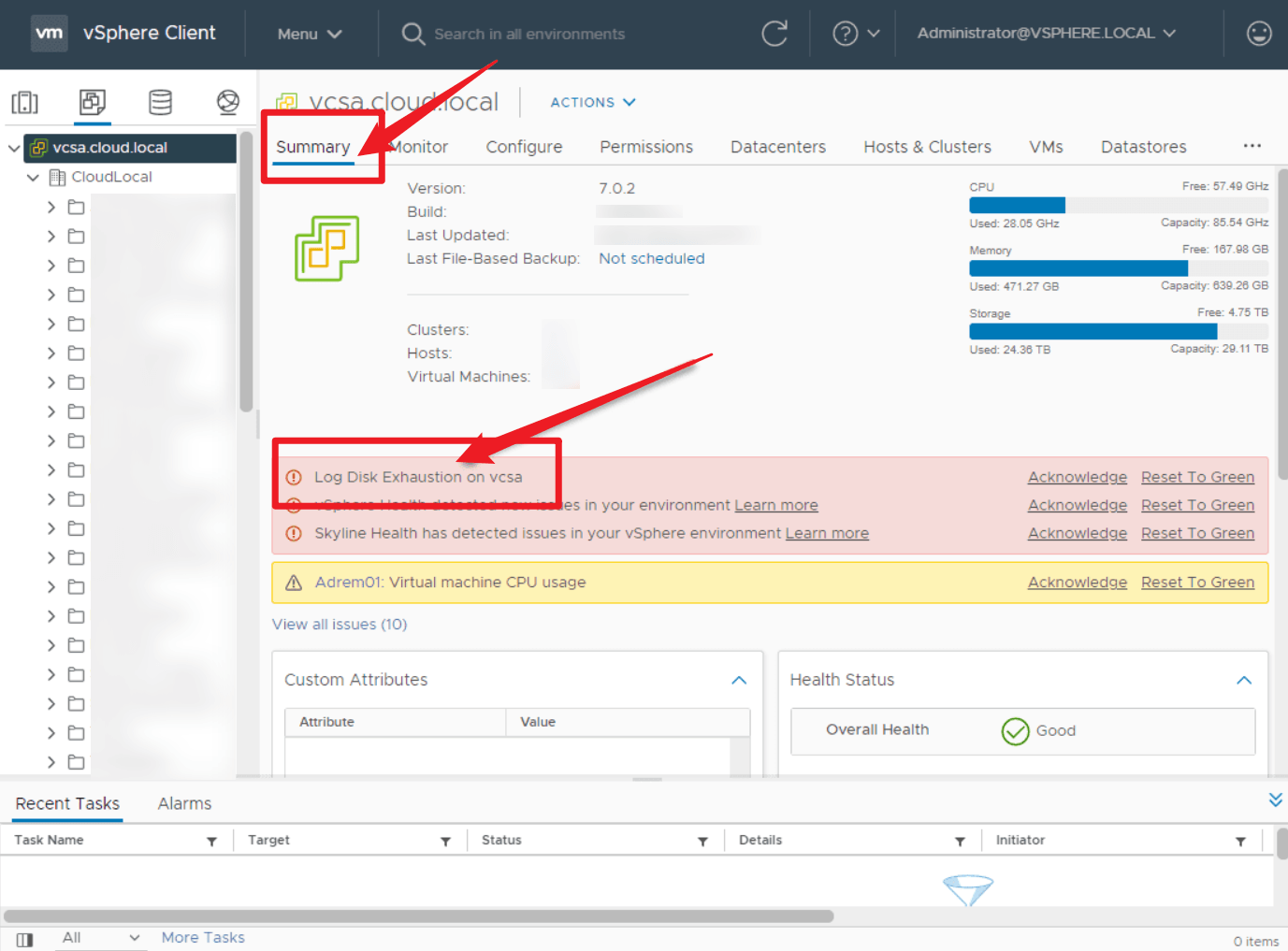
如何修复 vCenter 6.x / 7.x / 8.x 上的日志磁盘耗尽问题
2026-07-20
2026-07-20
2026-07-17
2026-07-16
大多数 VMware 环境看起来一切正常——直到出问题为止。一台主机无响应、一个数据存储空间用尽,或者 VM 性能在数天内悄然下降,却无人察觉。
良好的 VMware 监控能够在这些问题演变为事故之前发现它们。本指南涵盖需要跟踪的关键指标、如何设置实用的监控工作流,以及 2026 年最适合 vSphere 环境的工具。
VMware 监控是持续跟踪 ESXi 主机、vCenter Server 以及运行您应用程序的虚拟机的过程。
在共享的虚拟化环境中,问题不会孤立存在。单个过载的 VM 可能拖垮整个主机,而一个逐渐填满的数据存储可能同时导致多个工作负载离线。监控让您能够在这些问题升级之前发现它们。
自 Broadcom 收购以来,风险更高了。许多组织现在面临更高的许可成本和更大的资源优化压力。
基于这些原因,VMware 监控变得比以往任何时候都更加重要。它不仅仅是一个最佳实践,更是维护 VMware 环境性能、可用性和成本效率的关键组成部分。

构建一个坚实的监控框架需要分层策略。单一的指标无法告诉你一个分布式系统的完整健康状况。你需要将虚拟机管理程序级别的数据与每个 VM 内部实际发生的情况结合起来。
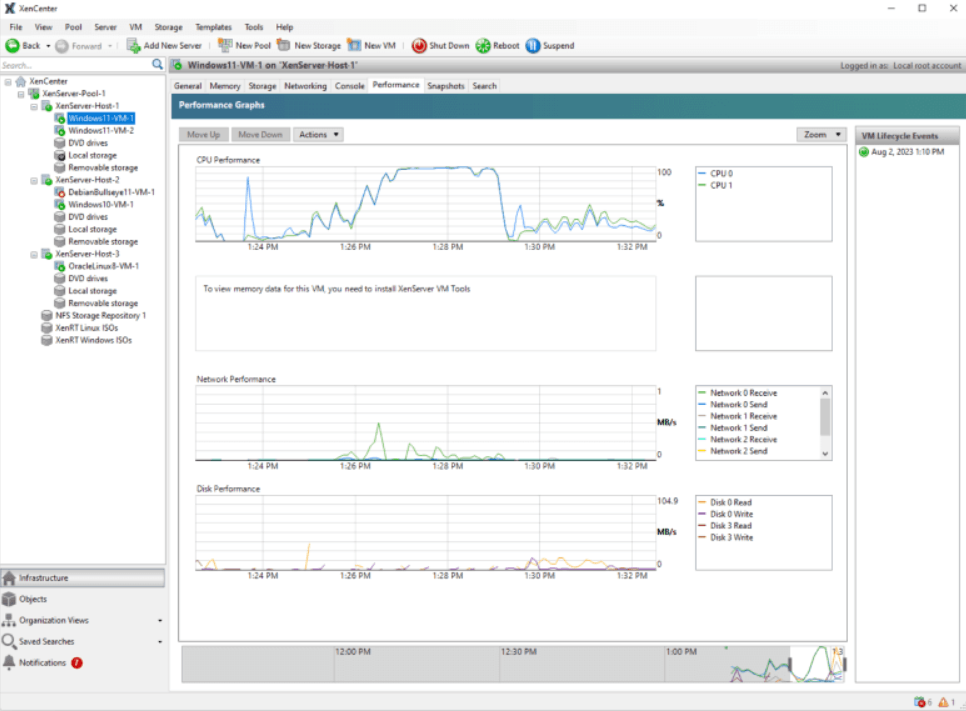
vSphere Client 性能图表是您的起点。无需额外软件。导航到任何 VM 或主机,选择 监控 > 性能 > 高级 以访问实时和历史数据。
这些图表允许您同时比较最多三个指标,并在堆叠视图和叠加视图之间切换——这对于发现相关性(如 CPU 峰值与存储延迟上升相关)非常有用。
VMware API 在虚拟机管理程序级别提供了强大的可见性,但它无法看到 VM 内部。为了获得完整的图景,请将虚拟机管理程序指标与客户机操作系统数据配对。
对 Windows 服务器使用 WMI,对 Linux 主机使用 SNMP 或 SSH。这让您可以比较虚拟机管理程序报告的内容与应用程序在客户机操作系统内部实际体验到的内容。
静态阈值可能具有误导性。90% 的 CPU 峰值对于 SQL 服务器在备份窗口期间可能是正常的,但对于 Web 网关来说却是一个危险信号。
在可能的情况下,使用具有 AI 或 ML 能力的工具来了解每个工作负载的“正常”状态。这可以减少误报,并帮助仅浮现真正需要关注的告警。
基线设置好后,为已知的性能问题设置告警。大多数管理员从以下阈值开始:
避免在工具和标签页之间不断切换。一个聚合了跨主机、VM 和数据存储数据的单一仪表板,让您更容易发现集群范围的模式——例如整个集群的延迟升高——这是单个 VM 视图会错过的。
如果您管理 VDI 工作负载,请在仪表板中包含一个 VMware Horizon 监控部分。将会话连接成功率与主机健康状态一起跟踪,帮助您快速区分网络问题和服务器问题。
对于大多数生产事故来说,手动响应太慢了。成熟监控设置的最后一步是将告警连接到自动化操作——无论是在您的 ITSM 平台中创建工单,还是触发 PowerCLI 脚本以添加存储或通过 vMotion 移动有问题的 VM。
一个健康的 vSphere 环境需要的不仅仅是检查主机是否在线。高效团队会跟踪特定指标,这些指标揭示了虚拟机管理程序管理共享资源的效率。
在虚拟化环境中,CPU 性能不仅仅是关于利用率百分比。更重要的问题是 VM 是否在需要运行时得到了调度。
vSphere 使用多种技术从空闲 VM 回收 RAM,这使得内存监控比物理服务器更细致入微。
存储是虚拟化环境中最常见的性能瓶颈之一。跟踪吞吐量和等待时间。
虚拟网络流量可能难以排查,因为其中大部分流量从未离开物理主机。
在集群级别,您需要了解资源如何平衡以及您的容错机制是否按预期工作。
快速参考:指标阈值
这些阈值被广泛用作起点,但正确的值将根据您的工作负载和存储类型而变化。
| 指标 | 警告 | 严重 |
|---|---|---|
| CPU 就绪时间 | 3% | 5% |
| 存储延迟 (GAVG) | 20 毫秒 | 30 毫秒 |
| 数据存储使用率 | 80% | 90% |
| 内存交换速率 | > 0 Kbps | > 500 Kbps |
| 网络丢包率 | 1% | 5% |
合适的监控工具取决于您的团队规模、技术专长和预算。一些组织从原生 vSphere 工具中获得所需的一切。其他组织则需要第三方平台来获得对 ESXi 主机或混合云环境的更深入可见性。
大多数管理员从其 vSphere 许可证附带的工具开始。
第三方工具通常提供与非 VMware 基础设施(如物理存储阵列或公有云平台)的更广泛集成,并且通常提供更灵活的仪表板和告警选项。
| 工具 | 最佳用途 | 关键特性 |
|---|---|---|
| PRTG | 中端市场团队 | 从统一仪表板监控 CPU、内存和数据存储容量 |
| Datadog | 混合云 | 在实时仪表板中统一云和本地 VMware 指标 |
| SolarWinds VMAN | 容量规划 | VM 规模调整建议和基于场景的容量规划 |
| ManageEngine OpManager | 自动化和合规性 | 结合性能监控、容量规划和合规性审计 |
| Netdata | 开源细粒度 | 跨 ESXi 主机、VM、数据存储和虚拟接口的每秒指标收集 |
| Veeam ONE | 备份和监控 | 将实时性能告警与备份任务健康状态的可见性配对 |
如何选择:
三个因素通常决定哪个工具合适:
正确的工具只能带你走这么远。您如何配置和维护监控策略决定了您是能及早发现问题,还是事后花时间解释宕机原因。
一个显著的性能峰值可能在 60 秒内发生并消失。如果您的监控工具每五分钟轮询一次,该事件将永远不会出现在您的数据中——让您无法在事后解释用户投诉。
大多数现代监控工具提供 30 秒的轮询间隔。如果您的工具没有,请考虑它是否能跟上生产 vSphere 环境的需求。
开箱即用的告警阈值很少对您的特定工作负载准确。域控制器和视频渲染服务器具有截然不同的正常 CPU 配置文件。
在配置自定义阈值之前,观察每个工作负载至少两周。这可以减少误报,并确保告警反映实际的应用程序行为,而不是通用默认值。
并非每个问题都需要立即响应。两层系统帮助您的团队确定优先级:
已开机但不再活跃使用的 VM 会消耗 CPU、内存和存储——在基于订阅的许可模式下,它们还可能增加您的成本。
定期检查您的 vCenter 清单,查找在 30 天窗口内 CPU 利用率接近零且没有磁盘活动的 VM。停用未使用的工作负载可以释放资源,并可能减少您的许可占用空间。
一些第三方监控工具按插槽数或 VM 数定价。当您扩展或整合环境时,请确保您的监控成本不会比您的基础设施增长得更快。
审查 Broadcom 持续的许可更新如何影响您的 VMware 堆栈以及其上的第三方工具。
监控告诉您什么时候出了问题。它无法在数据丢失后恢复您的数据。
许多 IT 团队在可见性工具上投入巨资,却将备份视为事后考虑。这是一个危险的缺口。在 VMware 环境中,真正的备份策略需要您的数据有一个独立的、单独的副本,无论生产环境发生什么,都可以恢复。
这就是专用备份解决方案变得必不可少的地方。i2Backup 是一个企业备份平台,旨在保护 VMware 环境以及物理服务器、数据库和非结构化数据——全部通过一个管理控制台完成。
对于需要不仅仅是备份的团队,英方软件还提供 i2Availability,这是一个高可用性解决方案,为 VMware 和其他虚拟化环境提供实时复制和自动故障转移,帮助您在生产故障发生时最小化 RPO 和 RTO。
监控和备份作为一对组合效果最佳。监控为您提供早期预警;备份为您提供恢复路径。它们共同构成了弹性 VMware 环境的基础。
有效的 VMware 监控不是一次性的设置。它是一个持续的过程,需要正确的指标、正确的工具以及随环境增长而发展的策略。
从基础知识开始:跨 ESXi 主机和 VM 跟踪 CPU 就绪时间、内存压力、存储延迟和网络健康状况。在设置阈值之前建立基线,使用告警层级减少噪音,并定期审计资源蔓延,这些资源会悄悄增加您的成本。
随着您的环境扩展或许可情况演变,重新审视您的工具。适用于 10 主机集群的方案可能不足以应对具有混合云扩展的多站点部署。
请记住:监控告诉您什么时候出了问题,但它无法恢复已经丢失的数据。将可靠的监控策略与可靠的备份解决方案(如英方软件的 i2Backup)配对,确保可见性和可恢复性协同工作,而不是孤立运行。

公告


邮件

销售





 沪公网安备31011202020864号
沪公网安备31011202020864号